David E. Wallace – Chief Scientist, Blue Pearl Software
There is a new development in the Clock Domain Crossing community that will affect both developers and users of CDC tools. For the past year, a working group of interested companies has been developing a new draft standard for CDC collateral that should allow tools from different vendors to cooperate in verifying different pieces of a large design. This CDC Working Group, organized under the Accellera Systems Initiative, released the 0.1 version of the draft standard for public review and comment on October 31st. The 0.1 version of the draft standard is primarily focused on representing CDC information at module boundaries. Future versions of the draft standard are expected to additionally address Reset Domain Crossings and Glitch Analysis.
You can find out more information, including where to download the draft standard and submit comments at https://accellera.org/news/press-releases/385-accellera-clock-domain-crossing-draft-standard-0-1-now-available-for-public-review. Note that the public comment period for this version of the draft standard will end on December 31st, 2023.
Blue Pearl Software has been actively participating in this working group and in the Preliminary Working Group that preceded it. We consider it important that users of our CDC tool should be able to interact with portions of the design that may be analyzed by other tools, whether to incorporate IP blocks or to use the design we analyze as part of a larger design. We have also benefited from broader discussions about CDC from users who are not part of our customer base.
Today, I would like to discuss one aspect of the draft standard that will require some changes in the way we do our CDC analysis. The draft standard allows for the possibility that users may define which clocks are synchronous to each other in a way that requires Non-transitive Clock Domains to describe.
What are Non-transitive Clock Domains?
Up until now, we at Blue Pearl have viewed Clock Domains as a form of equivalence class, in which clocks within a given clock domain are all synchronous to each other and asynchronous to any clock in a different domain. This equivalence class implies three properties of the binary relationship known as “is synchronous to”: the relationship is reflexive (clockA is synchronous to clockA), symmetric (if clockA is synchronous to clockB, then clockB is synchronous to clockA), and transitive (if clockA is synchronous to clockB, and clockB is synchronous to clockC, then clockA is synchronous to clockC). If all three properties hold, then we can group the clocks into distinct clock domains, where every clock is a member of one and only one domain.
A Non-transitive Clock Domain, then, is a case where the third property need not hold: where clockA is synchronous to clockB, and clockB is synchronous to clockC, but clockA and clockC need not be synchronous to each other. The primary use case that was discussed in the working group where users wanted this capability involves two different derived clocks whose clock periods do not evenly divide each other.
An example of this is shown in Figure 1 below. It involves a base clock in blue (“Base”) and two derived clocks, a divide by 3 clock in green (“÷3”) and a divide by 4 clock in orange (“÷4”). The rising edges of all three clocks are shown in the diagram to the right in terms of the number of cycles of the Base clock.
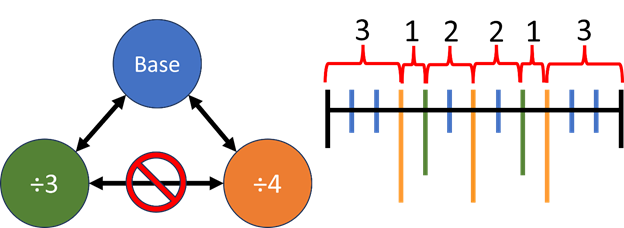
Figure 1: Base clock with two derived clocks that are treated as asynchronous to each other.
Now it is certainly possible to treat all three clocks as synchronous. They meet the definition we at Blue Pearl have used for synchronous clocks, in which two clocks are synchronous if the edges of both can be described using selection and translation of edges from a common ideal clock. However, there are reasons why a designer might choose to treat the two derived clocks as asynchronous instead.
To treat these clocks as synchronous and verify resulting paths in static timing analysis, the paths from registers clocked by ÷3 to registers clocked by ÷4 would need to be limited by the closest approach of two edges from those clocks, which would be a single cycle of Base (less any possible skew between the two). This is considerably shorter than the period of either of the two clocks involved. Moreover, because the two clock zones produce and consume data at different rates that are not clean multiples of each other, the user may want to use FIFOs on paths between the two to smooth out the flow of data. By treating the two clocks as asynchronous and using CDC analysis to verify that any paths between the two clocks are synchronized by FIFOs or other acceptable synchronizers, the user can verify that all data flowing between the two is properly synchronized.
To describe this kind of relationship, where “is synchronous to” is not necessarily transitive, the draft standard allows a clock to belong to more than one clock domain. Two clocks are considered synchronous if there is any domain that contains both clocks. Otherwise, they are considered asynchronous by default, and CDC analysis will check that any path between them is properly synchronized. The relationship between the clocks in Figure 1 can be described with two clock domains: domain1, which contains Base and ÷3, and domain2, which contains Base and ÷4. Thus, Base is considered synchronous to each of the two derived clocks, because it shares a domain with each, but the two derived clocks are considered asynchronous to each other because there is no single domain that contains both.
To represent these clock domains, the draft standard introduces a new command, set_cdc_clock_group. This command is similar to the SDC set_clock_groups command, however it defines a set of mutually synchronous clocks that constitute a single clock domain. Clocks are presumed asynchronous by default, unless they explicitly share a clock domain, which is the appropriate default for CDC analysis. (Technically, this draft of the standard is not defining a formal syntax for the command yet, but the syntax of a Tcl implementation is expected to look much like the pseudo-code in examples such as Figure 15 of the draft standard.)
What will this mean for our users? Users who are happy with conventional transitive clock domains should be able to continue to work much as they have been. To date, we have been using the SDC set_clock_groups command with nonstandard, more CDC-friendly semantics to define and save our clock domains. We intend to migrate to the new set_cdc_clock_group command as the primary way to represet clock domains going forward, while maintaining compatibility options for users who want to read SDC files with our old semantics.
For users who do have a need for non-transitive clock domains, they will soon be able to express those relationships in our tool using set_cdc_clock_group commands. There will likely be some new options that may help support this style of work. We are likely to release individual features as they become available, rather than waiting for one big release that incorporates the whole of the new draft standard. Indeed, the draft standard is very much a work in progress that will change in response to public feedback and continued work by the working group. We also want to hear from our users and potential users on what you consider the most important features for us to implement from this draft standard. Please let us know your questions and thoughts at V0-1Priorities@bluepearlsoftware.com.
Conclusion
It is our hope that adoption of this new interoperability standard will benefit our users by making CDC analysis more efficient and complete, regardless of which other tools are employed by our users or their IP vendors. We encourage you to read the proposed Accellera standard and give your input by December 31st using the links provided above. We also encourage interested companies to join Accellera and participate with us in the CDC Working Group to help define the next stages of the standard.
To learn more about the Visual Verification Suite please request a demonstration.